Thread dumps are vital artifacts to diagnose CPU spikes, deadlocks, memory problems, unresponsive applications, poor response times, and other system problems. There are great online thread dump analysis tools such as http://fastthread.io/ that can analyze and spot problems. But to those tools you need provide proper thread dumps as input. Thus in this article, I have documented 7 different options to capture thread dumps.
1. jstack
‘jstack’ is an effective command line tool to capture thread dumps. The jstack tool is shipped in JDK_HOME\bin folder. Here is the command that you need to issue to capture thread dump:
Where:
pid: is the Process Id of the application, whose thread dump should be captured
file-path: is the file path where thread dump will be written in to.
Example:
As per the example thread dump of the process would be generated in /opt/tmp/threadDump.txt file.
Jstack tool is included in JDK since Java 5. If you are running in older version of java, consider using other options
2. Kill -3
In major enterprises for security reasons only JREs are installed in production machines. Since jstack and other tools are only part of JDK, you wouldn’t be able to use jstack. In such circumstances, ‘kill -3’ option can be used.
Where:
pid: is the Process Id of the application, whose thread dump should be captured
Example:
When ‘kill -3’ option is used thread dump is sent to standard error stream. If you are running your application in tomcat, thread dump will be sent in to <TOMCAT_HOME>/logs/catalina.out file.
Note: To my knowledge this option is supported in most flavors of *nix operating systems (Unix, Linux, HP-UX operating systems). Not sure about other Operating systems.
3. JVisualVM
Java VisualVM is a graphical user interface tool that provides detailed information about the applications while they are running on a specified Java Virtual Machine (JVM). It’s located in JDK_HOME\bin\jvisualvm.exe. It’s part of Sun’s JDK distribution since JDK 6 update 7.s
Launch the jvisualvm. On the left panel, you will notice all the java applications that are running on your machine. You need to select your application from the list (see the red color highlight in the below diagram). This tool also has the capability to capture thread dumps from the java processes that are running in remote host as well.
 Fig: Java Visual VM
Fig: Java Visual VM
Now go to the “Threads” tab. Click on the “Thread Dump” button as shown in the below image. Now Thread dumps would be generated.
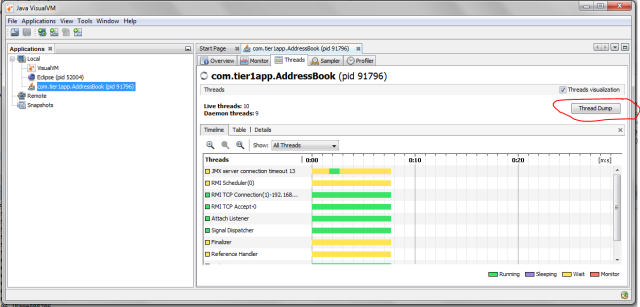
Fig: Highlighting "Thread Dump" button in the “Threads” tab
4. JMC
Java Mission Control (JMC) is a tool that collects and analyze data from Java applications running locally or deployed in production environments. This tool has been packaged into JDK since Oracle JDK 7 Update 40. This tool also provides an option to take thread dumps from the JVM. JMC tool is present in JDK_HOME\bin\jmc.exe
Once you launch the tool, you will see all the Java processes that are running on your local host. Note: JMC also has the ability to connect with java processes running on a remote host. Now on the left panel click on the “Flight Recorder” option that is listed below the Java process for which you want to take thread dumps. Now you will see the “Start Flight Recording” wizard, as shown in the below figure.
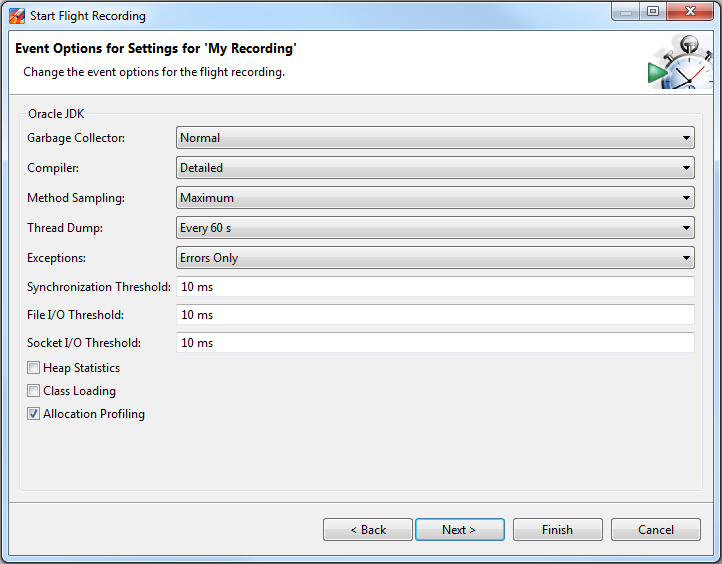 Fig: Flight Recorder wizard showing ‘Thread Dump’ capture option.
Fig: Flight Recorder wizard showing ‘Thread Dump’ capture option.
Here in the “Thread Dump” field, you can select the interval in which you want to capture thread dump. As per the above example, every 60 seconds thread dump will be captured. After the selection is complete start the Flight recorder. Once recording is complete, you will see the thread dumps in the “Threads” panel, as shown in the figure below.
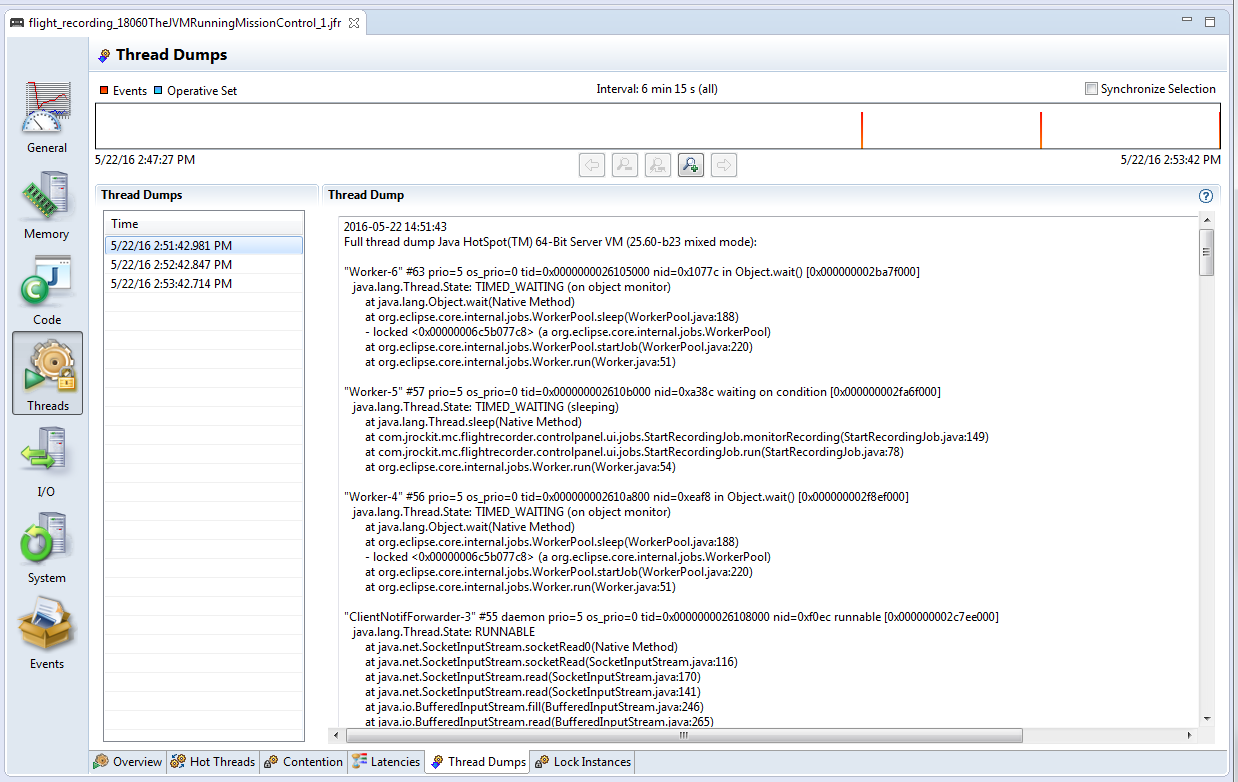
Fig: Showing captured ‘Thread Dump’ in JMC.
5. Windows (Ctrl + Break)
This option will work only in Windows Operating system.
- Select command line console window in which you have launched application.
- Now on the console window issue the “Ctrl + Break” command.
This will generate thread dump. The thread dump will be printed on the console window itself.
Note 1: in several laptops (like my Lenovo T series) “Break” key is removedJ. In such circumstances you have to google to find the equivalent keys for the “Break”. In my case it turned out that “Function key + B” is the equivalent of “Break” key. Thus I had to use “Ctrl + Fn + B” to generate thread dumps.
Note 2: But one disadvantage with this approach is thread dump will be printed on the windows console itself. Without getting the thread dump in a file format, it’s hard to use the thread dump analysis tools such as http://fasthread.io. Thus when you launch the application from the command line, redirect the output a text file i.e. Example if you are launching the application “SampleThreadProgram”, you would issue the command:
Instead launch the SampleThreadProgram like this
Thus when you issue “Ctrl + Break” thread dump will be sent to C:\workspace\threadDump.txt file.
6. ThreadMXBean
Since JDK 1.5 ThreadMXBean has been introduced. This is the management interface for the thread system in the Java Virtual Machine. Using this interface also you can generate thread dumps. You only have to write few lines of code to generate thread dumps programmatically. Below is a skeleton implementation on ThreadMXBean implementation, which generates Thread dump from the application.
7. APM Tool – App Dynamics
Few Application Performance Monitoring tools provide options to generate thread dumps. If you are monitoring your application through App Dynamics (APM tool), below are the instructions to capture thread dump:
1. Create an action, selecting Diagnostics->Take a thread dump in the Create Action window.
2. Enter a name for the action, the number of samples to take, and the interval between the thread dumps in milliseconds.
3. If you want to require approval before the thread dump action can be started, check the Require approval before this Action checkbox and enter the email address of the individual or group that is authorized to approve the action. See Actions Requiring Approval for more information.
4. Click OK.
2. Enter a name for the action, the number of samples to take, and the interval between the thread dumps in milliseconds.
3. If you want to require approval before the thread dump action can be started, check the Require approval before this Action checkbox and enter the email address of the individual or group that is authorized to approve the action. See Actions Requiring Approval for more information.
4. Click OK.
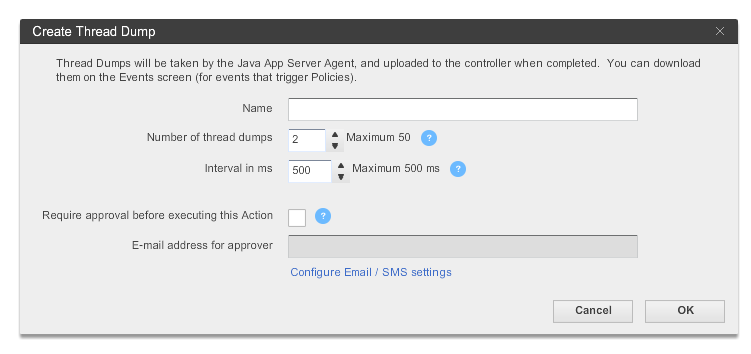
Fig: App dynamics thread dump capturing wizard
8. JCMD
The jcmd tool was introduced with Oracle’s Java 7. It’s useful in troubleshooting issues with JVM applications. It has various capabilities such as identifying java process Ids, acquiring heap dumps, acquiring thread dumps, acquiring garbage collection statistics, ….
Using the below JCMD command you can generate thread dump:
where
pid: is the Process Id of the application, whose thread dump should be captured
file-path: is the file path where thread dump will be written in to.
Example:
As per the example thread dump of the process would be generated in /opt/tmp/threadDump.txt file.
Conclusion
Even though 7 different options are listed to capture thread dumps, IMHO, 1. 'jstack' and 2. 'kill -3' are the best ones. Because they are:
a. Simple (straightforward, easy to implement)
b. Universal (works in most cases regardless of OS, Java Vendor, JVM version, etc.)












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}